葡萄新京 让矩阵归模拟, 让逻辑归数字! 这家中国团队再行界说了盘算推算机

黄仁勋的GPU,解一说念矩阵方程,要作念上亿次乘法。
一家中国公司,一步就给解了,用的是模拟盘算推算。
这家公司叫安纳智芯(Anatrix)。

往时几年,通盘这个词AI行业简直齐在往并吞个地点决骤。GPU、TPU、LPU、CPU……大师卷来卷去,内容上卷的其实如故数字盘算推算:
更多晶体管、更先进的制程、更大带宽、更高隐约。
但最近,咱们发现存一批公司,初始不按这个逻辑走了。
安纳等于其中之一。
他们采取的,是一个一经千里寂已久、但这两年又初始火热的地点:
模拟盘算推算。
这个主张听着新,其实少许齐不新。
早在数字盘算推算机大边界擢升之前,东说念主类就一经在研究模拟盘算推算。最近很火的存算一体、光盘算推算、量子盘算推算、类脑芯片,往大了说,内容上也齐属于这条道路。
之是以这两年再行被关切,一个很伏击的原因在于:
模拟盘算推算自然具备更高并行度、更低功耗,况且不像数字芯片那样高度依赖先进制程。
但它的问题也很彰着,数字盘算推算内容上处理的是0和1,只消能永诀上下电平,过错就能被束缚更动。
而传统模拟盘算推算由于是平直用物理信号示意信息。电压、电流、电导这些量在传播经由中,容易荟萃噪声和漂移。
矩阵边界越大,过错放大得越夸张。
往时几十年,数字盘算推算靠着摩尔定律沿路狂飙,精度被束缚“硬堆”上去;而模拟盘算推算诚然表面上更高效,却恒久困在精度问题里。
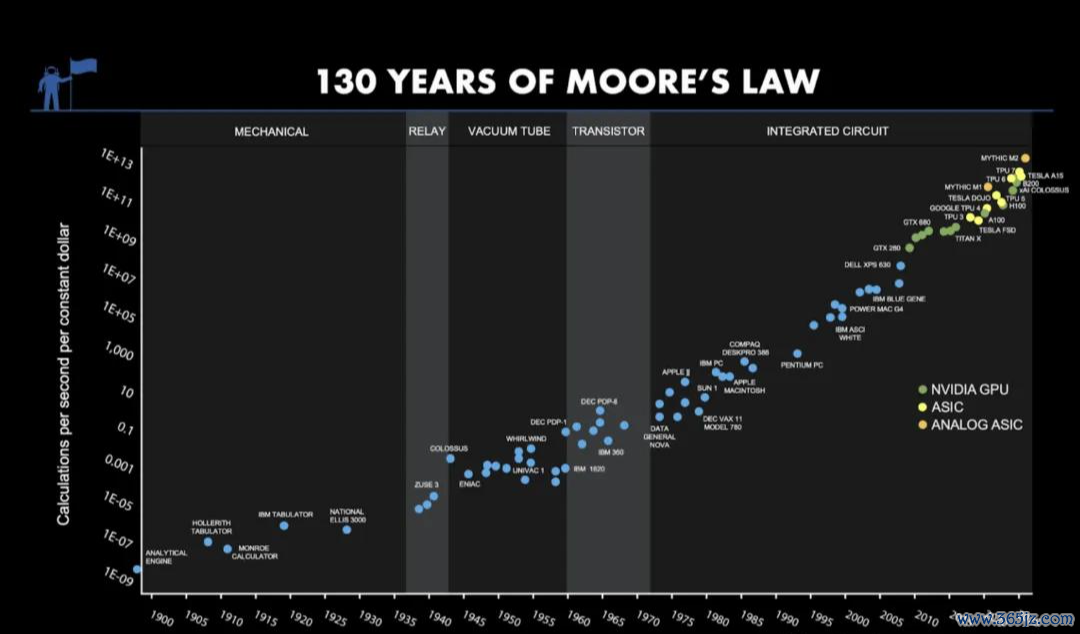
行业里以致一直有一个很流行的不雅点:模拟盘算推算很快、很省电,但不确凿。精度,也因此成了模拟盘算推算近几十年来最大的死结。
而安纳作念的,等于把它解开。
模拟盘算推算的精度,不再是问题了
往时近十年里,安纳的中枢科学家一直在作念并吞件事——
把模拟盘算推算的扫尾,作念得浪掷确凿。
前年,团队完成了精度忘形数字芯片水平的旨趣性考证,在模拟盘算推算边界达到断档式最初,而本年,有关芯良晌下一经干涉流片阶段。
在时间道路上,安纳走的是一条很是典型、但也很是“硬核”的模拟盘算推算道路:
基于存储器阵列,搭建非冯诺依曼架构芯片。
浅易来说,等于把矩阵方程平直映射进物理电路,让电路自己成为方程求解器。
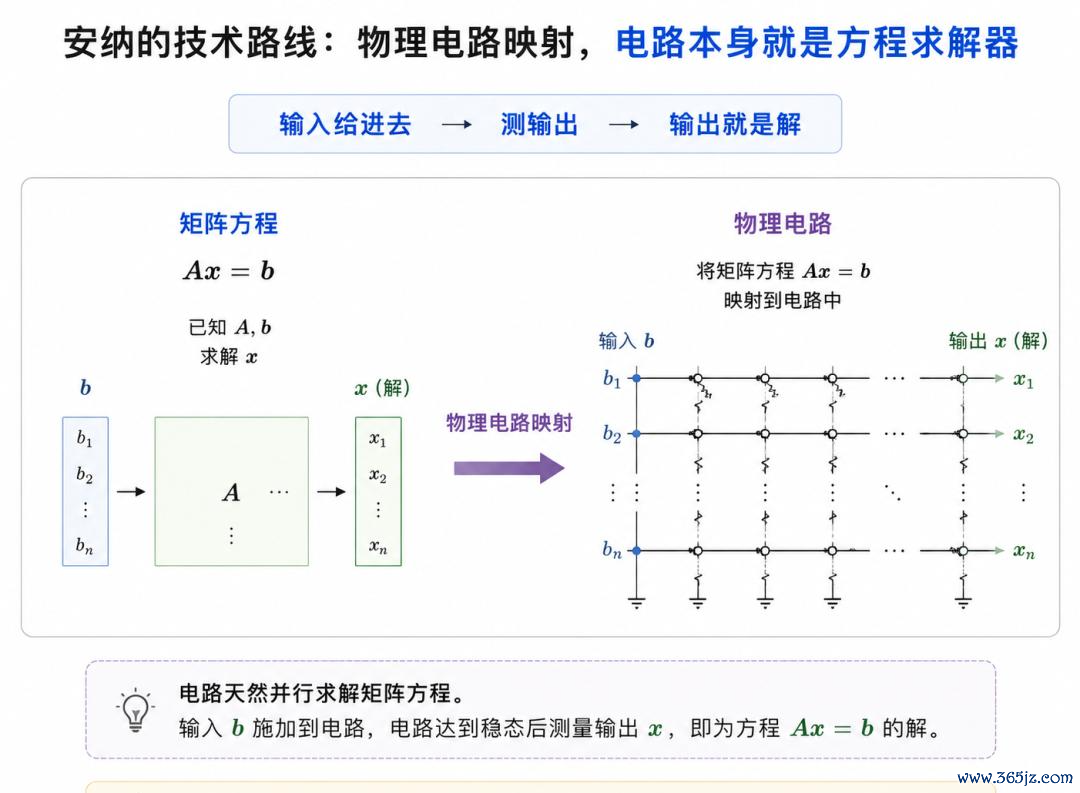
输入给进去,测输出,输出等于解。
也正因如斯,那些GPU没主义平直求解、只可靠海量迭代迫临的矩阵方程,在安纳这里,不错一步完成,并保握精准。
(注:GPU拿到一个512×512的矩阵方程后,第一件事并不是“平直解”。它会先把问题辨别、转置、分解,再滚动成海量矩阵乘加运算,通过一轮轮迭代迟缓迫临谜底。通盘这个词经由,时常需要上亿次乘法。)
但非凡念念的是。
即便精度问题初始被贬责,今天大深广模拟盘算推算公司依然莫得采纳这条路。
博亚体育2026世界杯中国官网像Unconventional AI、Normal Computing、EnCharge AI这些近两年最受关切的模拟盘算推算创业公司,主打的依然是低功耗、存算一体或者特定场景加快。

(注:模拟盘算推算正在再行取得本钱商场关切。2025年底,主打低功耗模拟芯片的 Unconventional AI在种子轮便取得Lightspeed Venture Partners和a16z商量领投的4.75亿好意思元融资,估值接近45亿好意思元;专注热力学盘算推算的Normal Computing于本年3月完成由三星领投的5000万好意思元融资;而存算一体公司EnCharge AI前年也完成了最初1亿好意思元的B轮融资。)
这背后其实对应着两种完满不同的研究玄学。
一种念念路是接管模拟盘算推算存在过错,在低精度条款下寻找“够用”的行使场景。
另一种念念路,则是先把精度作念到极限,再琢磨后果和成本。
安纳属于后者。
在与量子位疏导时,团队反复提到一个不雅点:
通盘盘算推算平台的发展历史,简直齐是先把精度作念到天花板,再把柄场景需求向下作念弃取。
数字盘算推算亦然如斯,AI模子闇练里,先有FP32,再向下兼容FP16、INT8、INT4。
要是一初始就在低精度里寻找“够用”,许多才调可能长久莫得契机被考证。
从上世纪80年代末的类脑盘算推算,到其后的模拟神经网罗,再到今天的存算一体,雷同的故事其实一经反复出现过许屡次。
是以,并不是追求精度这件事有争议,而是在往时很永劫刻里,由于模拟盘算推算精度低是固有的,大师停留在这一层面,存在剖判上的偏差,于是只可退而求其次。
而安纳率先完成了剖判上的打破,他们确凿想作念的,等于把高精度模拟盘算推算推向可用。
通盘东说念主齐在作念乘法,葡萄新京安纳想把“除法”补回归
除了对精度的气派,安纳和其他模拟盘算推算公司的不同,还在于他们选了一个完满不同样的地点:
矩阵求逆。
今天作念模拟盘算推算的公司,非论是存算一体、模拟CIM,如故各式类脑、光盘算推算道路,简直齐在作念矩阵乘法。
这其实很好贯通,因为通盘这个词AI产业,内容上等于斥地在矩阵乘法之上的。
一方面,GPU自己就极其擅长矩阵乘法;另一方面。大模子推理,也简直全是矩阵乘法,是以
通盘这个词行业的念念路齐很当然——
既然模拟盘算推算更省电、更并行,那就拿它去替代一部分GPU的矩阵乘法,但安纳并莫得这样作念,他们采纳了更第一性的矩阵求逆。
那么,矩阵乘法和矩阵求逆有啥不同样呢?
浅易来说,矩阵乘法,内容上是“知因求果”。权重已知、参数已知,乘起来、加起来,临了得到扫尾。
而矩阵求逆反过来。扫尾一经知说念了,但中间确凿的参数、权重、景象未知,你需要反过来把它求出来,从扫尾反推原因。
对应到大模子里也很好贯通:矩阵乘法更多对应推理,而矩阵求逆则更接近闇练。
因为闇练内容上,等于已知输入和输出,再反过来寻找中间最妥贴的参数。

(注:今上帝流数字盘算推算的作念法,依然是把原来需要平直求解的问题,滚动成海量矩阵乘法,再通过束缚迭代去迫临谜底。)
事实上,矩阵求逆并不局限于大模子闇练。试验寰球里确凿难的问题,许多其实齐是“逆问题”。
比如,机器东说念主为什么会颠仆?自动驾驶怎样从传感器数据里还原真实景象?通讯系统怎样从搀和信号里恢归附始信息?
这些问题,底层齐在作念并吞件事:从扫尾反推原因。
而这,恰正是GPU不擅长的。因为在数字芯片体系里,并不存在“原生矩阵求逆”这个算子。它的作念法,内容上是绕。
先把一个求逆问题辨别,再滚动成海量矩阵乘法,然后通过束缚迭代,一轮轮迫临最终谜底。
是以GPU不是“平直解”,而是在“迫临解”,这亦然为什么,咱们前边会看到阿谁“一亿步”和“一步”的辨别。
为了愈加潜入地贯通这两者的互异,安纳还给咱们打了一个很形象的譬如。
比如你要建长城。矩阵求逆就像“砖”。而数字芯片手里其实莫得砖。它惟有沙子、土壤、原料。
是以它得先和泥、烧制、成型,临了才调得到一块砖,再拿这块砖去建长城。
模拟盘算推算芯片,则是平直把砖给你。你无谓再从沙子初始。是以这不是“快少许”或者“省少许”的区别,而是盘算推算范式自己不同。
一个是在束缚迭代迫临。
一个则是原生求解。
安纳想作念的,等于把这块缺失了许多年的“砖”,再行补回归。
让矩阵归模拟,让逻辑归数字
说到临了,一个很试验的问题摆在眼前:
模拟盘算推算这块“砖”,到底怎样插进今天一经高度纯属的AI基础按序里?
安纳给出的谜底很浅易:让矩阵归模拟,让逻辑归数字。
据了解,他们的模拟芯片在接口、数据体式和互联神色上,齐兼容现存GPU体系,不错平直接入今天一经scale起来的AI Infra和算力中心。
更伏击的是,它不依赖起先进制程。
当数字芯片还在3nm、2nm上延续向物理极限迫临时,模拟盘算推算某种意思意思意思意思上一经跳出了那套“拼晶体管、拼工艺、拼堆叠”的竞争逻辑。
而一朝矩阵求逆这块“砖”确凿补上,它带来的变化,可能会比假想中更大。
机器学习里的优化问题、具身智能的及时教学放胆、自动驾驶的景象猜度、6G通讯里的信号回复、端侧AI的在线学习……这些系统背后,内容上齐在高频求解矩阵方程。
往时许多问题不是不成作念,而是太慢、太贵、太耗电。
而矩阵求逆一朝概况被原生、高精度、低功耗地完成,许多往时只可放在云霄、只可离线闇练、只可近似求解的事情,可能齐会初始发生变化。
是以回头再看,安纳想作念的,其实不仅仅一颗“更快更省电的芯片”。
他们确凿想切入的,是下一代智能系统最底层的盘算推算神色。
2012年,东说念主们第一次意志到,GPU不仅能绘图,还能闇练神经网罗。
AI时期由此开启。
而今天,安纳试图回答的是另一个问题:
要是矩阵乘法界说了往时十年的AI,那么模拟盘算推算和矩阵求逆,会不会界说下一代智能系统?
至少当今葡萄新京,他们一经站在了这个问题的最前排。